
スキャンピーのOCRは微妙

普段書籍をPDF化するためにスキャンピーはたくさんお世話なっています。非常にありがたい限りです。
しかし、スキャンピーのOCRの精度はそこまで高くはないように感じています。たしかに文字認識等は95%程度はあると思うのですが、妙な空白や空行、英語は記号として解釈されたりしてしまって微妙なシーンがあります。
今回はこの問題に対してのアプローチとして試してみたので共有の意味を込めてブログに残します。
前提
- Windows, MacOS特にどちらも区別しない
試したこと(OCR処理)
DN_SuperBook_PDF_Converter(Windows + GPU)
最初に試したのはこちらでした。yomitokuも含めた高性能OCRも搭載していて、かなり期待できたのですが、途中でエラーが発生し、いろいろ試してみたのですが原因がわからず途中で諦めてしまいました。
OCRmyPDF-appleOCR(Mac) - ✅採用
Claudeに相談したら以下の回答がきました。縦書きもいけるとのことだったので、こちらを採用しました。精度もかなり高いことが期待できるのと、Mac単体で行けるのが大きかったです。
方法1:OCRmyPDF + Apple Vision(Macのみ・精度最高)
概要
OCRmyPDF のプラグインとして Apple の Vision Framework を使う方法で、Tesseract など他のオンデバイスエンジンより精度・速度ともに優れています。縦書き日本語に対応した livetext モードも利用可能です。 GitHub
手順
bash# OCRmyPDFとプラグインをインストール
brew install ocrmypdf
pip install ocrmypdf-appleocr
# 実行(--force-ocrで既存レイヤーを上書き)
ocrmypdf -l jpn --plugin ocrmypdf_appleocr --force-ocr input.pdf output.pdf
評価
精度:◎(Apple の Live Text エンジンは現状オンデバイス最高水準)
コスト:無料
制限:Mac限定、Python環境が必要
実際の精度差比較
スキャンピー
次 に第二 の問題 に移 ります。構 築主義が ある「べ き」社会 のあ り方 とか,
人 々が従 う「べ き」ス タィルを指 し示す主義 として使われた り,ま たはそ うし
たムー ドが醸成 された りする危険性の問題です。
あ りとあ らゆる ものが実体的にあるのでな くて,関 係の中で生 じているとい
つた ことは,(強 引に理屈 をつ ければ)言 お うとして言 えないことはあ りませ
ん。sOcial cOnstructiOnismが 浅 はかな仕方で流行す ることによつて,こ れ ま
で individualと みなされがちだった もの を,人 間関係の「おかげさま」で生 じ
ているのだか ら,そ の独立 自存性の強調は「 よくない」 とみなすムー ドを生み
出 しかねません。個人の尊厳 とか,自 由 とか,平等 とか,人 権 といった価値的
な構築物 に敵対す る言説 となるか もしれ ません。文字認識は高いが、変な文字になったり、英語のoと0の認識が怪しく、謎の空白も目立つ
OCRmyPDF+AppleVision
次に第二の問題に移ります。構築主義がある「べき」社会のあり方とか、
人々が従う「べき」スタイルを指し示す主義として使われたり、またはそうし
たムードが醸成されたりする危険性の問題です。
ありとあらゆるものが実体的にあるのでなくて、関係の中で生じているとい
ったことは、(強引に理屈をつければ)言おうとして言えないことはありませ
ん。 social constructionism が浅はかな仕方で流行することによって、これま
でindividualとみなされがちだったものを、人間関係の「おかげさま」で生じ
ているのだから、その独立自存性の強調は「よくない」とみなすムードを生み
出しかねません。個人の尊厳とか、自由とか、平等とか、人権といった価値的
な構築物に敵対する言説となるかもしれません。かなり綺麗にOCR処理ができていることがわかる
NDLOCR-Lite(Windows/Mac)
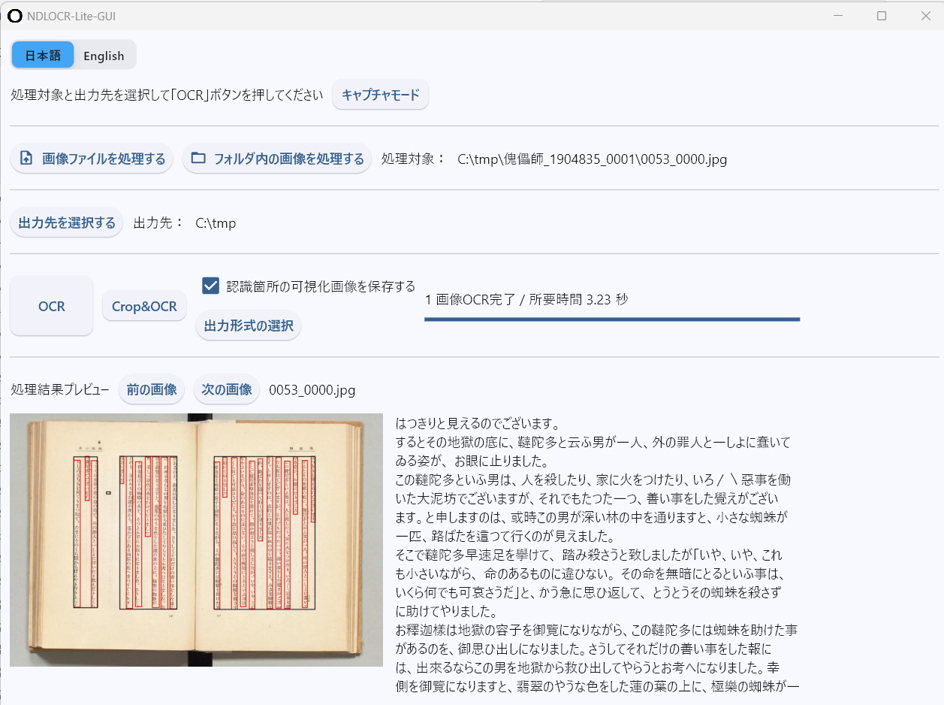
こちらも精度が高く、Macだけで完結はしたのですが、画像がぼやける(dpiが低くなる)等の課題があり見送りました
スキャンピーOCR
次 に第二 の問題 に移 ります。構 築主義が ある「べ き」社会 のあ り方 とか,
人 々が従 う「べ き」ス タィルを指 し示す主義 として使われた り,ま たはそ うし
たムー ドが醸成 された りする危険性の問題です。
あ りとあ らゆる ものが実体的にあるのでな くて,関 係の中で生 じているとい
つた ことは,(強 引に理屈 をつ ければ)言 お うとして言 えないことはあ りませ
ん。sOcial cOnstructiOnismが 浅 はかな仕方で流行す ることによつて,こ れ ま
で individualと みなされがちだった もの を,人 間関係の「おかげさま」で生 じ
ているのだか ら,そ の独立 自存性の強調は「 よくない」 とみなすムー ドを生み
出 しかねません。個人の尊厳 とか,自 由 とか,平等 とか,人 権 といった価値的
な構築物 に敵対す る言説 となるか もしれ ません。文字認識は高いが、変な文字になったり、英語のoと0の認識が怪しく謎の空白も目立つ
NDLOCR-Lite
次に第二の問題に移ります。 構築主義がある べき」 社会のあり方とか,
人々が従う 「べき」 スタイルを指し示す主義として使われたり, またはそうし
たムードが醸成されたりする危険性の問題です。
ありとあらゆるものが実体的にあるのでなくて, 関係の中で生じているとい
ったことは, 言おうとしてはおうとして言おうとして言えないことはありませ
ん。 social constructionismが浅はかな仕方で流行することによって, これま
でindividualとみなされがちだったものを,人間関係の「おかげさま」で生じ
ているのだから,その独立自存性の強調は「よくない」とみなすムードを生み
出しかねません。 個人の尊厳とか, 自由とか, 平等とか, 人権といった価値的
な構築物に敵対する言説となるかもしれません。精度はOCRmyPDFと同等な感じがしますが、途中「が消失していることが確認できます
処理
全体像
- OCRmyPDF-appleOCRでOCR処理
- ghostscriptでPDF圧縮
- おわり
大まかには2ステップだけです。ここらへんをClaudeにごにょごにょ相談してスクリプトを書いてもらいます。
実行コマンド
OCRmyPDF-appleocr
以下のコマンドをベースにスクリプトを作成してもらいました。縦書きと横書きでオプションの有無があるので、そこも考慮するようにしてください。
~/ocr-env/bin/ocrmypdf -l jpn \
--plugin ocrmypdf_appleocr \
--force-ocr \
--appleocr-recognition-mode livetext \
input.pdf output.pdfghostscript
150dpiくらいで圧縮します。OCRmyPDFだと再度画像化してOCRにするのでかなりファイルサイズが大きくなります(800dpiくらいでやられます)。ghostscriptで圧縮させてあげましょう。
gs -dBATCH -dNOPAUSE -sDEVICE=pdfwrite \
-dCompatibilityLevel=1.4 \
-dPDFSETTINGS=/ebook \
-sOutputFile=compressed.pdf input.pdf私は後から気づいたのでアレですが、OCRmyPDFを実行する時点でも圧縮するコマンドは可能です。ただどっちが処理が早いかと聞かれると、わかりません。
さいごに
スキャンピーのOCRオプションは正直付けなくてもいいかな...と思ってしまいました。実際に納品されたら自分でOCR処理してしまえば、今の時代は十分ですね。